构建知识库#
在现实世界中,各类知识通常是保存在文件中的(如 PDF、Word、PPT 等)。然而这种半结构化数据无法被大模型解析也不适合构建知识库,因此我们需要事先将其转化为结构化的文本数据。在这个教程中,我们将使用一个简单的示例来展示如何将一批 PDF 文件转化为结构化数据。
小技巧
如果您已经拥有结构化数据,您可以跳过这个教程。
使用 FlexRAG 内置的命令行工具来解析文档#
FlexRAG 提供了一个命令行工具 prepare_corpus 来帮助用户将各类文件解析为结构化数据。本教程将以一篇 Arxiv 上的论文为例,展示如何使用 FlexRAG 内置的命令行工具来解析 PDF 文件。
首先使用以下命令从 Arxiv 上下载一篇论文:
wget https://arxiv.org/pdf/2502.18139.pdf
随后,您可以运行下面的命令将这篇论文解析为结构化的知识库数据:
python -m flexrag.entrypoints.prepare_corpus \
document_paths=[2502.18139.pdf] \
output_path=knowledge.jsonl \
document_parser_type=markitdown \
chunker_type=sentence_chunker \
sentence_chunker_config.max_tokens=512 \
sentence_chunker_config.tokenizer_type=tiktoken \
sentence_chunker_config.tiktoken_config.model_name='gpt-4o'
在这段命令中,我们指定了以下参数:
document_paths:待解析的文件路径列表,这里我们仅解析了一篇论文;output_path:解析结果的输出路径,该路径应当以.jsonl,.csv或.tsv结尾;文档解析器的类型,这里我们使用了
markitdown;文本切分器的类型,这里我们使用了
sentence_chunker;文本切分器的最大长度,这里我们设置为 512;
文本切分器使用的分词器类型,这里我们使用了 OpenAI 的
tiktoken;分词器使用的模型名称,这里我们使用了
gpt-4o。
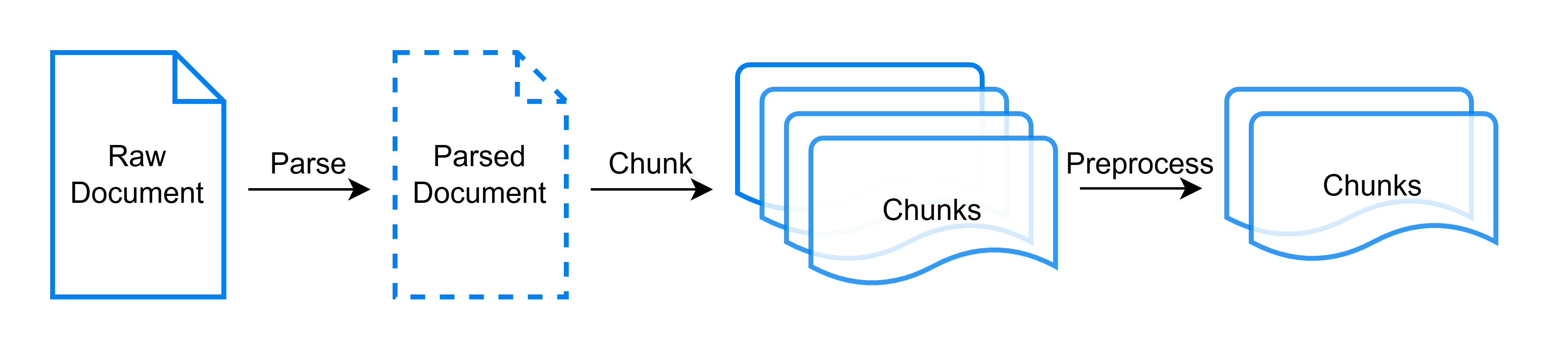
执行完上述命令后,您就可以看到 PDF 文件被解析为了一个 JSONL 文件。如下图所示,在这个过程中,FlexRAG 共计执行了三个步骤:
解析:将文件解析为结构化数据
切分:将结构化数据中的长文本段落切分为适合处理的短文本段落
预处理:对切分后的文本段落进行预处理和过滤
小技巧
您可以查看文档 FlexRAG Entrypoints 了解更多关于 prepare_corpus 命令的信息。
小技巧
您可以查看文档 Preparing the Retriever 了解如何为您的知识库构建检索器。