高级教程:从互联网上获取相关信息#
网络检索器 WebRetriever 是一类特殊的检索器,这种检索器可以从互联网上获取信息。具体来说,可以是利用搜索引擎(如谷歌、必应等)来检索网页并读取相关信息,也可以是通过点击、跳转等操作自动浏览网页并获取相关信息。由于可以访问互联网,网络检索器在时效性和检索信息的广度上具有显著的优势,这使得网络检索器非常适合用于构建您的个人助手。
在本教程中,我们奖项您展示如何在您的项目中加载或构建网络检索器。
重要
由于使用计算机程序从互联网上获取信息有可能违反部分地区法律,或部分网站使用了反爬虫技术来阻止您的访问,请您确保您在使用网络检索器时的合法性。
使用 FlexRAG 内置的网络检索器#
使用网络检索器最简单的方式就是直接使用 FlexRAG 中内置的网络检索器。FlexRAG 中内置了以下两种网络检索器:
简单网络检索器
SimpleWebRetriever:该检索器通过互联网搜索引擎来获取相关信息,并通过网页读取器WebReader来将 HTML 内容转化为对大模型友好的内容。维基百科检索器
WikipediaRetriever:该检索器直接通过维基百科检索相应的实体,该检索器是从ReACT项目中获取的灵感。
在这篇教程中,我们将会向您展示如何使用 SimpleWebRetriever 来从互联网上获取信息。
使用搜索引擎获取最相关片段#
大多数搜索引擎都会在搜索结果中提供一个文本片段,该片段通常是网页中的一小段和用户查询最相关的文本。在很多情况下,这个片段中包含了回答用户问题所需的信息。在 FlexRAG 中,您可以使用下面的代码来载入一个网络检索器,该检索器将会为您的查询搜索5个最相关的网页,同时返回相应的片段。
from flexrag.retriever import SimpleWebRetriever, SimpleWebRetrieverConfig
config = SimpleWebRetrieverConfig(
top_k=5, # Retrieve top 5 webpages
search_engine_type="ddg", # Use DuckDuckGo as the search engine
web_reader_type="snippet", # Return the snippet provided by the search engine
)
retriever = SimpleWebRetriever(config)
ctxs = retriever.search("Who is Bruce Wayne?")[0]
在上面的代码中,我们使用了 DuckDuckGo 搜索引擎,FlexRAG 中也提供了其它搜索引擎的接口,您可以查看 SearchEngineConfig 获取更多详细信息。
获取完整网页信息#
很多时候,仅使用搜索引擎提供的片段并不足以获取充足的信息。这种情况下,您也许会希望从完整的网页中获取信息。然而网页通常由 HTML 写成,其中包含了大量的样式标签和无关信息,直接将这样的网页送入大模型让其阅读可能会引入大量噪声,同时提高大模型推理成本。为了解决这一问题,FlexRAG 引入了网页读取器 WebReader 这一模块来将复杂的网页转换为大模型友好的内容。下面的例子向您展示了如何使用网页读取器来获取完整的网页信息:
from flexrag.retriever import SimpleWebRetriever, SimpleWebRetrieverConfig
from flexrag.retriever.web_retrievers import JinaReaderConfig
config = SimpleWebRetrieverConfig(
top_k=5, # Retrieve top 5 webpages
search_engine_type="ddg", # Use DuckDuckGo as the search engine
web_reader_type="jina_reader", # Extract all information from the HTML webpage
jina_reader_config=JinaReaderConfig(
api_key="<your-jina-api-key>", # Jina API key
)
)
retriever = SimpleWebRetriever(config)
ctxs = retriever.search("Who is Bruce Wayne?")[0]
在这段代码中,我们使用了 JinaReader 作为我们的网页读取器,这是一个由 Jina AI 公司提供的 API 服务,该服务可以帮助您将 HTML 页面转换为大模型友好的文本。您可以从 Jina AI 官网中获取您的 API 密钥。
FlexRAG 也提供了其它类型的网页读取器,比如获取网页截图的 ScreenshotWebReader 和使用本地模型的 JinaReaderLM。您可以访问 WebReaderConfig 文档以获取更多有关网页读取器的信息。
获取网页截图#
由于现在的视觉大模型(VLM)在处理图像信息方面取得了长足进步,即使是网页截图这样复杂的图片也可以被妥善处理。因此 FlexRAG 也提供给了一个独特的网页读取器用于将网页转换为截图。下面的代码将向您展示如何使用 ScreenshotWebReader 将 DuckDuckGo 检索到的网页转换为截图。
from flexrag.retriever import SimpleWebRetriever, SimpleWebRetrieverConfig
from flexrag.retriever.web_retrievers import JinaReaderConfig
config = SimpleWebRetrieverConfig(
top_k=5, # Retrieve top 5 webpages
search_engine_type="ddg", # Use DuckDuckGo as the search engine
web_reader_type="screenshot", # Capture the screenshot of the webpage
)
retriever = SimpleWebRetriever(config)
ctxs = retriever.search("Who is Bruce Wayne?")[0]
在运行了上述代码后,您将会获取到和您的查询最相关的五个网页的网页截图,该截图将以 PIL.Image.Image 的形式保存在 RetrievedContext 中。
备注
网页截图这一功能需要安装 playwright。请确保您在使用该功能前安装了 playwright。
定义您自己的网络检索器#
如果您希望构建您自己的网络检索器,您可以继承 WebRetriever 这个类,并实现其中的 search 方法。当然,您也可以借助 FlexRAG 中提供的大量网络访问的工具来定义您的网络检索器。
FlexRAG 中的网络检索工具#
FlexRAG 提供了大量工具来帮助您构建您的网络检索器:
互联网资源搜索器
WebSeeker:一个用于根据查询来寻找相关网络资源的模块。网页读取器
WebReader:一个用于从原始网页中提取有效信息的模块。网络下载器
WebDownloader:一个用于下载网络资源的模块。
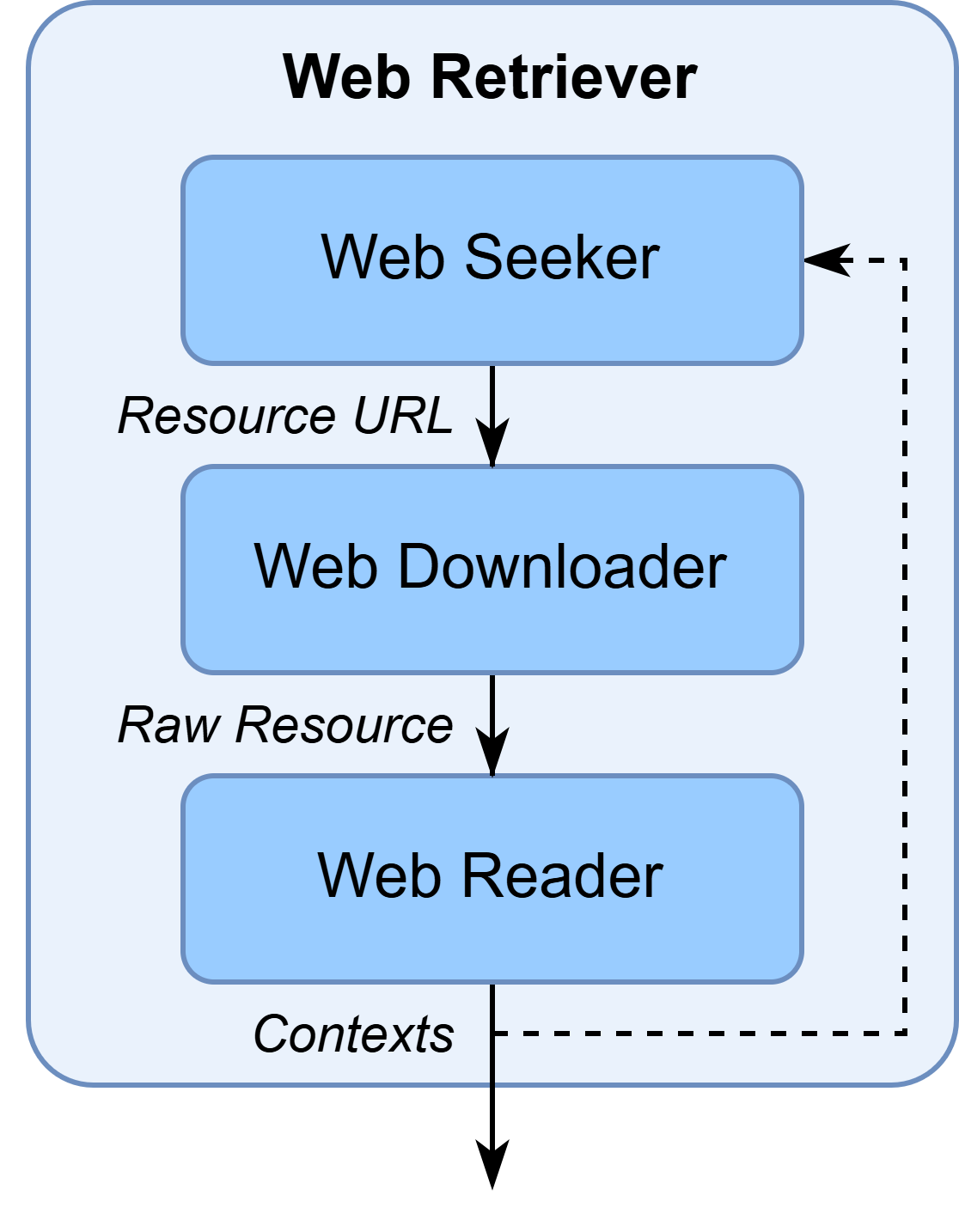
您可以访问Web Seeker、Web Reader、以及 Web Downloader 的文档以获取更多相关信息。